Image of Google's infrared camera technology United States Patent and Trademark Office
The other day my colleague Kee Malesky turned me on to an incredibly interesting article from the New Scientist website about the granting of patent 7508978. What's so important about Patent 7508978 you ask? It's the patent that explains how Google's proprietary book scanning technology works.
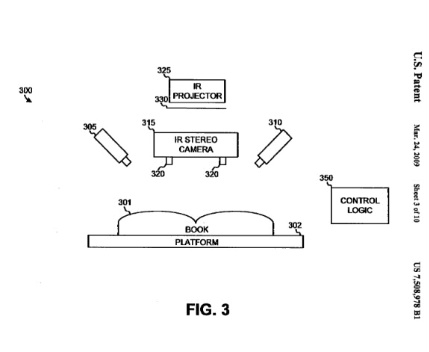
... Before Google came on the scene, book scanning was a tedious process that sometimes resulted in the death of a book. The software used to scan books, called Optical Character Recognition software or OCR for short, required each page of the book to be flat. Now anyone who's ever opened a book knows it's next to impossible for a book to lie flat without some sort of device. One solution to the problem was to use glass plates that individually flattened each page, but this method wasn't very efficient. The other solution was to chop off the book's binding, but that method destroyed the book. How was one to go about scanning a book quickly and efficiently without destroying it?
...Google created some seriously nifty infrared camera technology that detects the three-dimensional shape and angle of book pages when the book is placed in the scanner. This information is transmitted to the OCR software, which adjusts for the distortions and allows the OCR software to read text more accurately.
via NPR: The Secret Of Google's Book Scanning Machine Revealed.
Sunday, May 3, 2009
Secret Of Google's Book Scanning Machine Revealed
Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment